Linux文本三剑客
grep sed awk的基本使用
grep
Global search REgular expression and Print out the line
文本搜索工具,根据用户指定的“模式(过滤条件)“对目标文本进行逐行过滤
由正则表达式的元字符和文本字符所编写出的过滤条件
基本格式
1 | |
BRE基本正则和ERE扩展正则
基本正则
1 | |
扩展正则(需要带上-E)
| 字符 | 作用 |
|---|---|
| + | 1或n次 |
| [1-5]+ | 字符1或n词(同上) |
| ? | 0或者1 |
| | | 或关系 |
| () | 分组(含前向引用等用法) |
| a{n,m}类 |
1 | |
sed
Stream Editor(字符流编辑器),流编辑器
结合正则对文本快速增删改查,主要功能为过滤和取行
基本格式
1 | |
| 参数 | 作用 |
|---|---|
| -n | 取消默认sed输出,常和p一起用 |
| -i | 直接将修改结果写入文件。若不用-i,则sed修改的是内存数据 |
| -e | 多次编辑,不需要管道符了 |
| -r | 支持正则扩展 |
内置字符
sed的内置命令字符用于对文件进行不同的操作功能,如对文件增删改查
| 内置字符 | 作用 |
|---|---|
| a | append,对文本追加,在指定行后面添加一或多行文本 |
| d | delete,删除匹配行 |
| i | insert,插入文本,在指定行前添加一或多行 |
| p | print,打印匹配行的内容,常与-n搭配 |
| c | 替换,c后接字符串,可以取代n1,n2之间内容 |
| s/正则/替换内容/g | 匹配正则内容,然后替换内容,g代表全局匹配 |
匹配范围
| 范围 | 解释 |
|---|---|
| 空地址 | 全文处理 |
| 单地址 | 指定文件的某一行 |
| /pattern/ | 被匹配到的每一行 |
| 范围区间 | 10,20 10到20行,10,+5第10行向下5行,/pattern1/,/pattern2/ |
| 步长 | 1~2,表示1、3、5、7、9、奇数行,2~2两个步长,表示2、4、6、8、10、偶数行 |
平常用到:
- 针对某一行替换
1 | |
- 找到某行再处理其下n行
1 | |
awk
具有文本格式化能力,同时也是一门简单的编程语言,具有变量、数组、判断、循环等功能
基本格式
1 | |
1 | |
打印文本的第一列(默认用空格分隔)
- $0代表一整行
$NF表示当前分割最后一列,倒数第二列$(NF-1)
选项
| 参数 | 作用 |
|---|---|
| F | 指定分隔符 |
| v | 定义 or 修改一个awk内部变量 |
| f | 从脚本中读取awk命令 |
| 更多选项详见手册 |
内置变量
| 内置变量 | 含义 |
|---|---|
| $n | 当前第n个字段 |
| $0 | 整行 |
| FS | 字段分隔符,默认空格 |
| NF | 当前一共多少个字段 |
| NR | 当前记录数,行数 |
一次输出多列
1 | |
自定义输出内容
awk必须外层单引号,内层双引号
内置变量$1、$2都不能添加双引号,否则会识别为文本,尽量别加引号
1 | |
输出整行信息
1 | |
显示文件第5到7行
1 | |
显示行号和每行数据
1 | |
awk分隔符有两种
- 输入分隔符(FS)默认空格
- 输出分隔符(OFS)
内置变量
- 内部变量在输出中不需要
$,但时其代表一个数字时加上$,即可表示$number
1 | |
下面是详细版本的内置变量
| 内置变量 | 作用 |
|---|---|
| FS | 输入字段分隔符,默认空格 |
| OFS | 输出字段分隔符,默认空格 |
| RS | 输入资料分隔符(输入换行符),指定输入时的换行符 |
| ORS | 输出记录分隔符(输出换行符),输出时用指定符号代替换行符 |
| NF | number of field,当前行的字段个数 |
| NR | 行号 |
| FNR | 各文件分别计数的行号 |
| FILENAME | 当前文件名 |
| ARGC | 命令行参数个数 |
| ARGV | 数组,命令行给定的参数 |
分隔符修改
1 | |
修改输出符
1 | |
修改RS
- RS输入分隔符,修改后碰见修改字符就输出分割
1 | |
修改ORS
- ORS输出分隔符,awk默认每一行结束就要添加
回车换行符,即ORS默认为回车换行
1 | |
RS ORS一起用
1 | |
ARGV
1 | |
自定义
1 | |
格式化输出
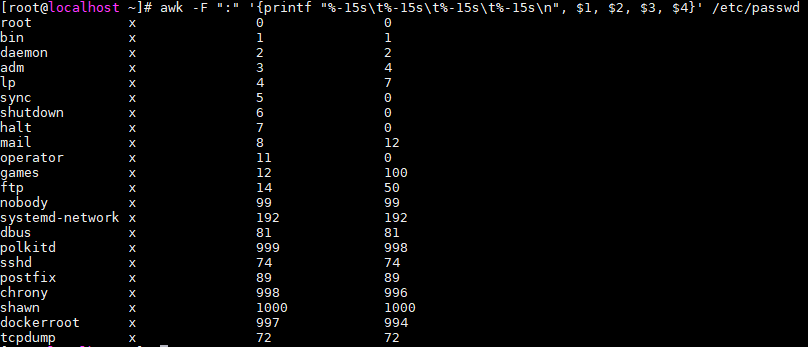
printf格式化
- 用法同c语言中的printf,print自带换行,printf不带
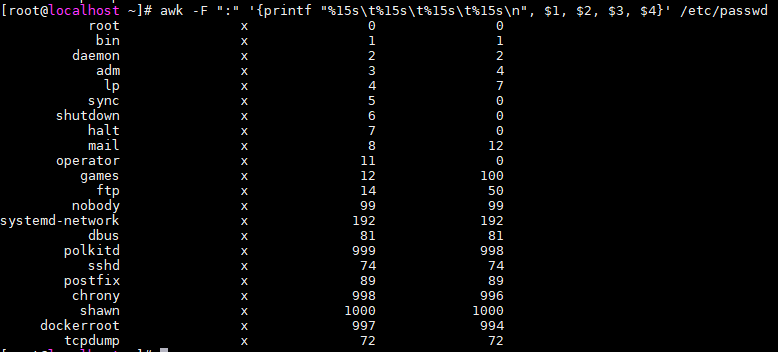
- 用
-左对齐
模式pattern
空模式
关系运算符模式
关系运算符 作用 示例 <、<=、==、!=、>=、> 比较 x!=y ~ 匹配正则 x~/regex/ !~ 不匹配正则 x!~/regex/ 1
2
3awk -F ":" '/root/ {printf "%-15s\t%-15s\t%-15s\t%-15s\n", $1, $2, $3, $4}' /etc/passwd # 找出含有root的行
awk -F ":" '/root/,/docker/ {printf "%-15s\t%-15s\t%-15s\t%-15s\n", $1, $2, $3, $4}' /etc/passwd # 找出root和docker之间的行
- BEGIN/END模式
- BEGIN模式是处理之前执行的动作
- END模式是处理完所有行之后执行的动作
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!